MNER 多模态命名实体识别
数据集
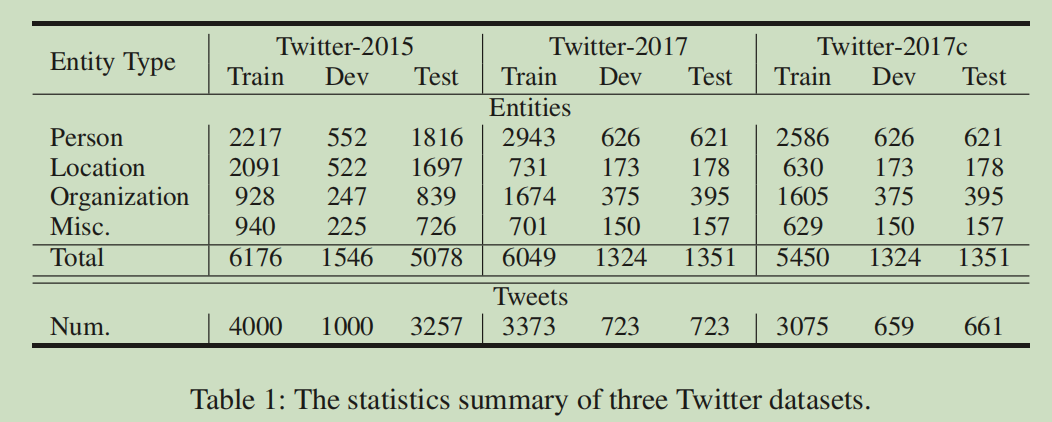
Baseline
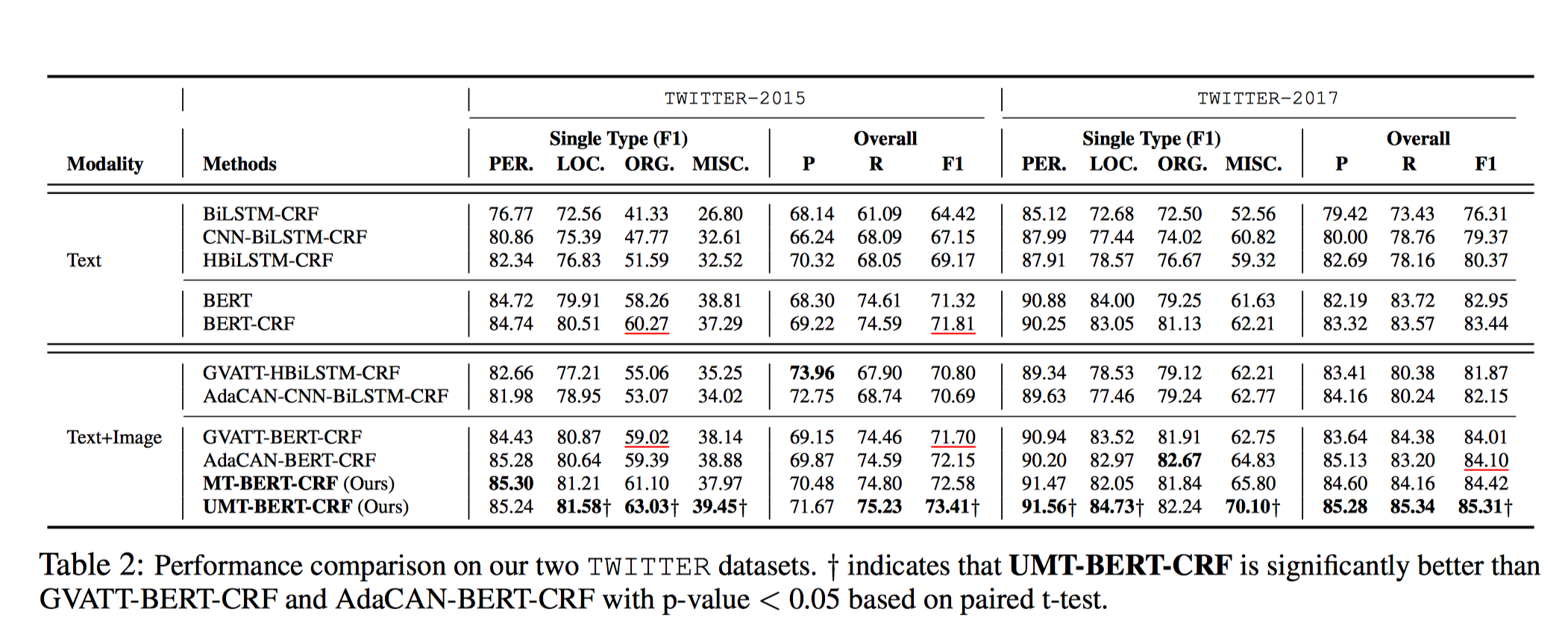
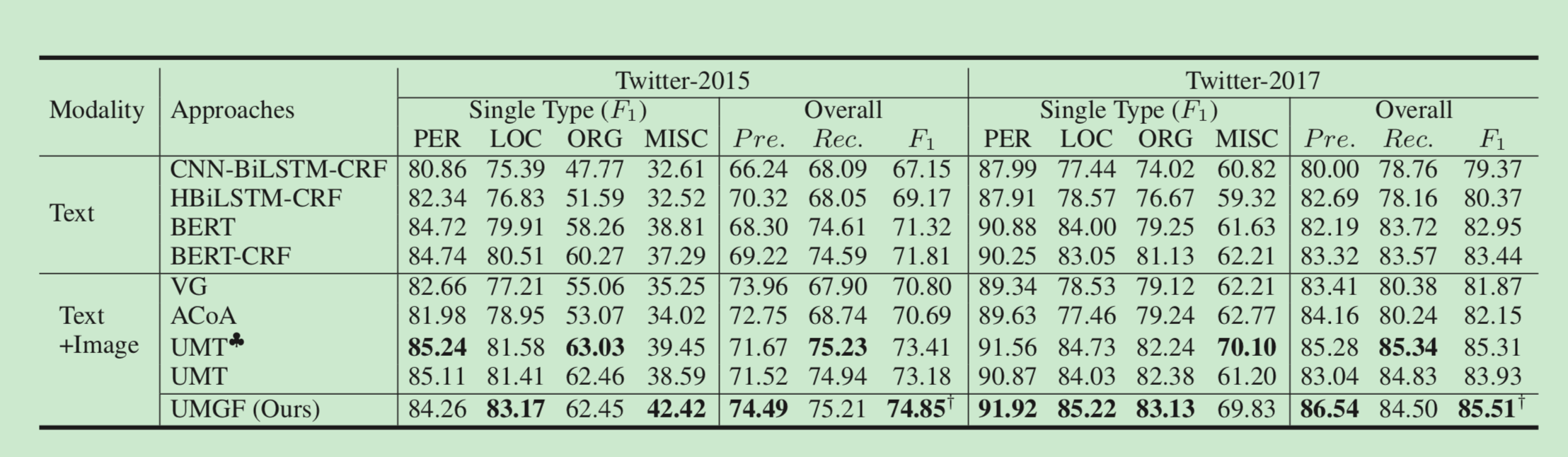
实验结果:
| twitter2015 | twitter2017 | |
|---|---|---|
| BasicModel | 72.614 | 84.002 |
| MMNerModel(bert+crf+ViT) | 72.820 | 84.303 |
| UMT | 73.41 | 84.42 |
| HMT-12 | 73.09 | 84.25 |
| HMT-last | 73.20 | 84.25 |
| MYUMT | 73.83 | 86.18 |
| alpha | beta | twitter2017 |
|---|---|---|
| 0.8 | 0.5 | 83.96 |
| 0.8 | 0.8 | 84.19 |
| 1 | 1 | 84.24 |
参考资料
实体关系的联合抽取总结
https://zhuanlan.zhihu.com/p/366767181
2020
Improving Multimodal Named Entity Recognition via Entity Span Detection with Unified Multimodal Transformer
现有方法问题
- 没有考虑一词多义的上下文表示。
- 虽然当前方法基于多模态建模获得基于文本的视觉表示,但是在最后隐藏层依然还是只基于文本的表示来进行预测,没有将视觉信息融合进去。
- 视觉偏差:通常图片只涉及文本中的某一个两个实体,并不涉及其他实体,如果一味的将视觉信息融合进所有实体的识别当中,会导致相关实体识别准确率很高,但是其他实体识别率降低。
模型
首先通过Bert和ResNet分别得到文本和图片的上下文向量和视觉特征,之后通过MMI(Transformer的跨模态版本)产生关于文本的视觉表征和关于图片的文本表征。最后通过辅助边界检测任务消除视觉偏差问题。
贡献
- 对于MNER任务首次提出了多模态的Transformer。
- 基于多模态Transformer,设计了一个MNER联合框架,为消除视觉偏差而引入了实体跨度检测辅助任务。
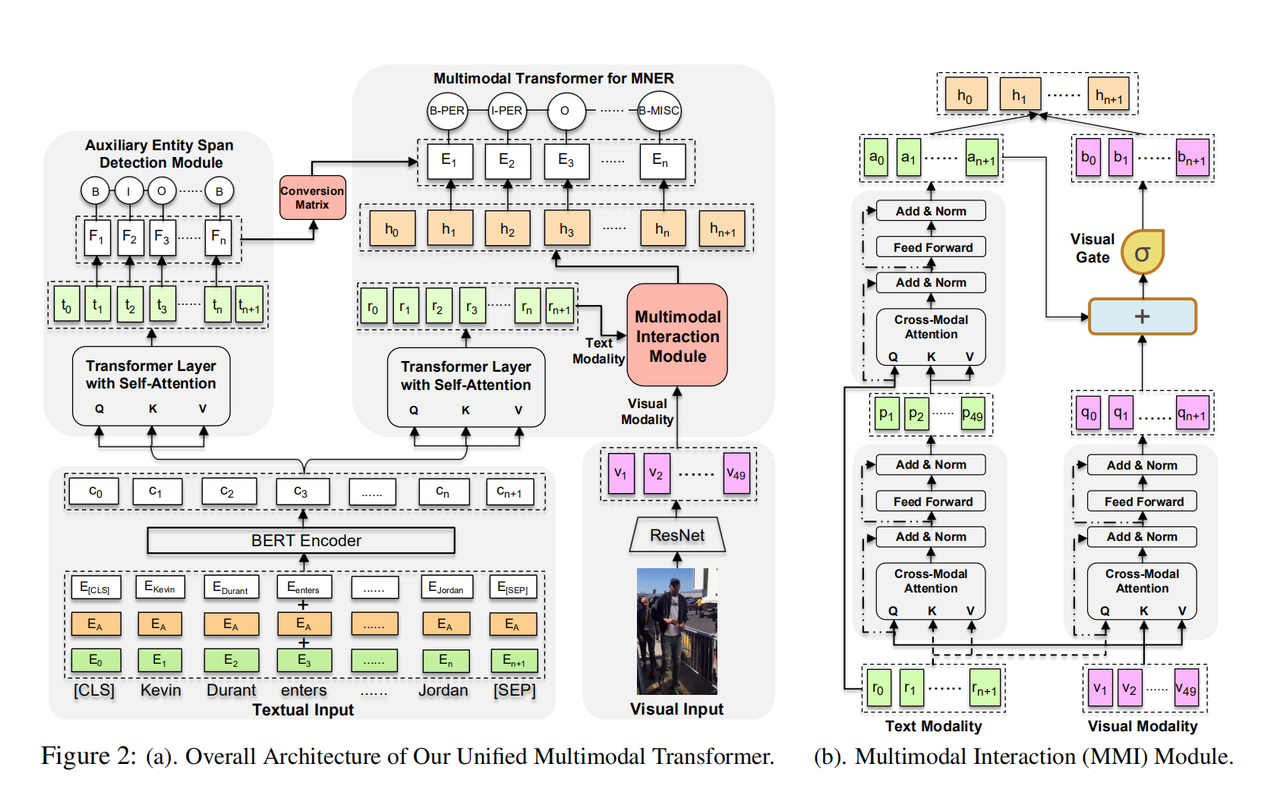
实验结果
2021
Multi-modal Graph Fusion for Named Entity Recognition with Targeted Visual Guidance
模型
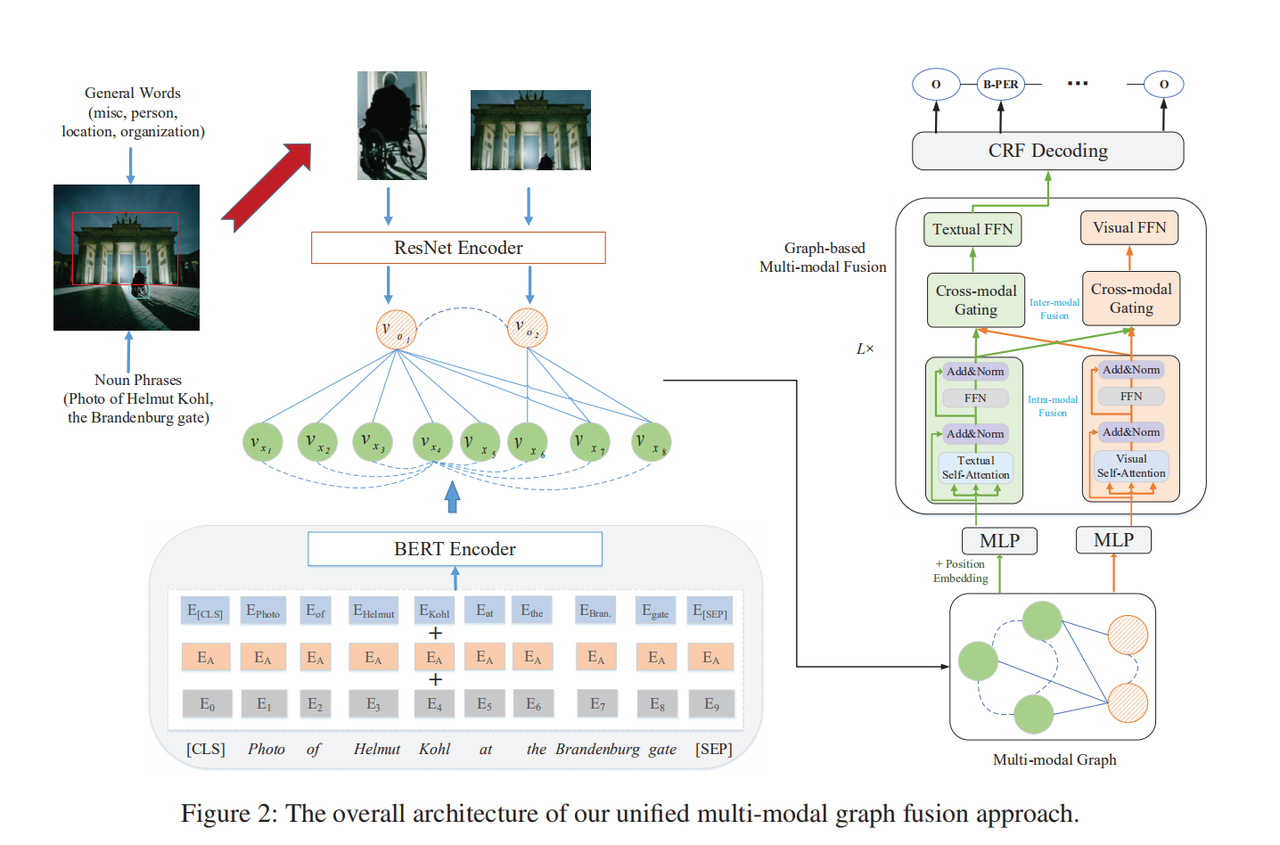
AAAI 2021 | RpBERT:引入关系传播机制,多模态命名实体识别任务表现优异
评价
只是建模用了图,实际没有用GNN来来训练
Think
| 能否引入外部知识库,比如Freebase Dictionary,来解决关联图像噪声 |  |
|---|---|
| 对于无图像的推文不输入默认图像,而是0向量,借鉴short cut思想,直接在融合模块不进行模态间融合,在预测层,直接将默认第一层输入,使预测结果尽量贴合BERT-CRF模型 | 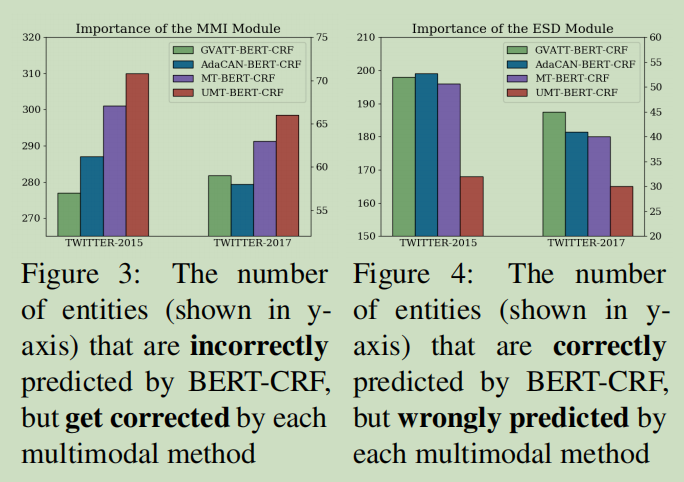 |
- 如何降低抽象图像或者卡通图像等图像噪声?
- 加个单独的分类器判断图像是否是卡通图和表情包,如果是,就降低图像的对文本的权重。
- 适当增加图像相关联的词语获得的注意力权重。
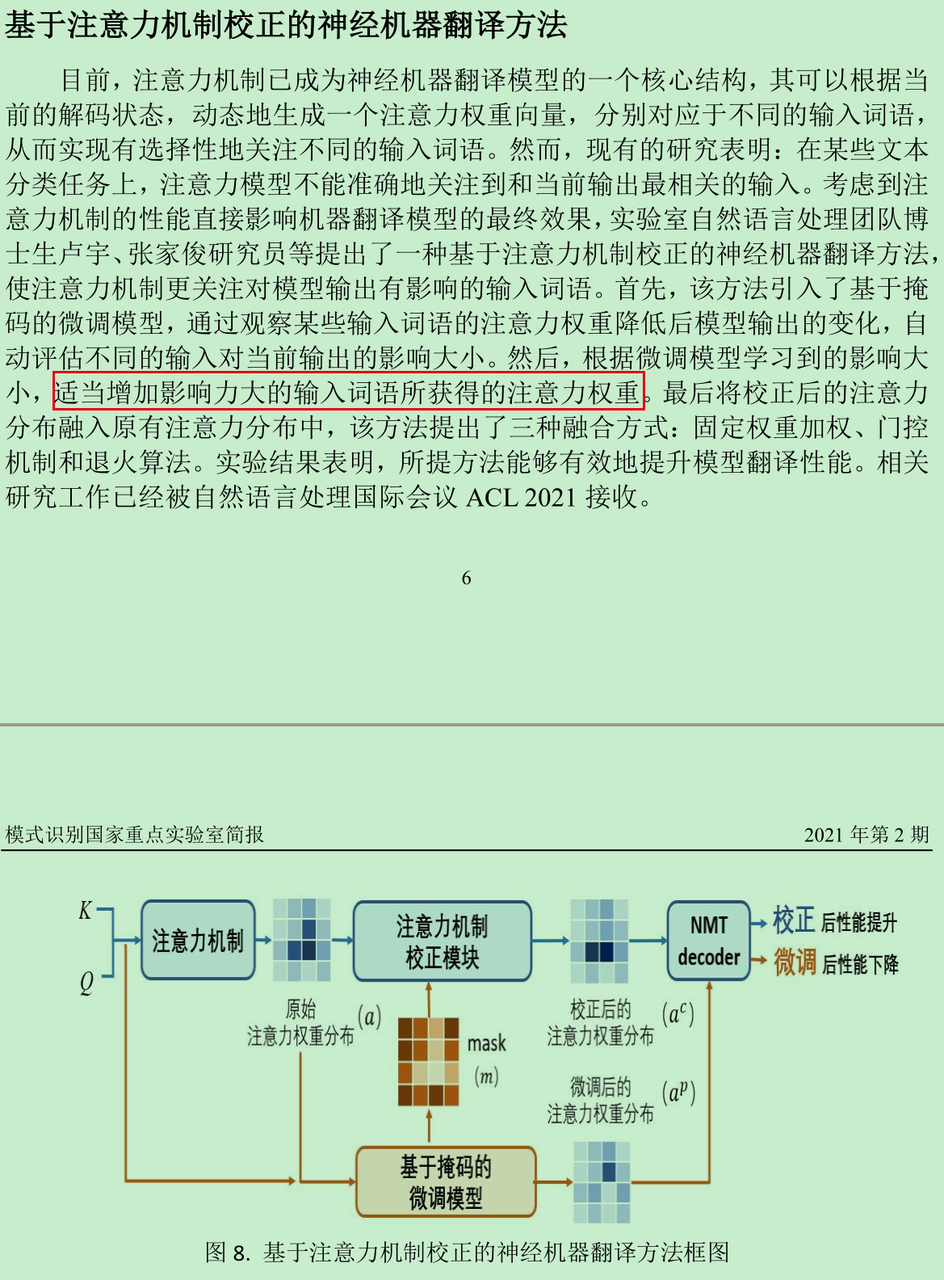
- 兼容BERT-CRF的UMT
参考文献
- A Survey on Deep Learning for Named Entity Recognition
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
 wechat
wechat alipay
alipay
Comment